More Retail Ltd. (MRL)는 수익이 수십억 달러에 달하는 인도의 4 대 식료품 소매 업체 중 하나입니다. 인도 전역에 걸쳐 22 개의 대형 슈퍼마켓과 624 개의 슈퍼마켓으로 구성된 매장 네트워크를 보유하고 있으며 13 개의 유통 센터, 7 개의 과일 및 채소 수거 센터, 6 개의 스테이플 가공 센터의 공급망을 통해 지원됩니다.
이러한 대규모 네트워크에서 MRL은 적절한 경제적 가치로 적절한 제품 품질을 제공하는 동시에 고객 요구를 충족하고 운영 비용을 최소화하는 것이 중요합니다. MRL은 AI 분석 파트너로서 Ganit과 협력하여 더 정확하게 수요를 예측하고 자동 주문 시스템을 구축하여 매장 관리자의 수동 판단의 병목 현상과 결함을 극복했습니다. MRL은 Amazon Forecast 를 사용 하여 예측 정확도를 24 %에서 76 %로 높임으로써 신선 농산물 범주에서 낭비를 최대 30 %까지 줄이고 재고 비율을 80 %에서 90 %로 높이고 총 수익을 25 %.우리는 두 가지 주요 이유 때문에 이러한 비즈니스 결과를 달성하고 자동화 된 주문 시스템을 구축하는 데 성공했습니다.
- 실험 능력 – Forecast는 기존 모델과 ML 모델을 모두 포함하는 다양한 회귀 변수 및 모델 유형을 사용하여 200 개 이상의 실험을 실행하는 유연한 모듈 식 플랫폼을 제공합니다. 팀은 Kaizen 접근 방식을 따랐으며 이전에는 실패한 모델에서 학습하고 성공했을 때만 모델을 배포했습니다. 우승 모델이 배포되는 동안 측면에서 실험이 계속되었습니다.
- 변경 관리 – 비즈니스 판단을 사용하여 주문하는 데 익숙한 카테고리 소유자에게 ML 기반 주문 시스템을 신뢰하도록 요청했습니다. 체계적인 채택 계획을 통해 도구의 결과가 저장되고 도구가 체계화 된 케이던스로 작동되어 채워진 현재 재고가 제 시간에 식별되고 기록됩니다.

신선한 제품은 유통 기한이 짧기 때문에 신선한 농산물 카테고리에 대한 수요를 예측하는 것은 어렵습니다. 과도한 예측을 통해 상점은 오래되거나 과도하게 익은 제품을 판매하거나 대부분의 재고를 폐기합니다 ( 수축 이라고 함 ). 예상치 못한 경우 제품이 품절되어 고객 경험에 영향을 미칠 수 있습니다. 고객은 쇼핑 목록에서 주요 품목을 찾을 수없는 경우 장바구니를 포기할 수 있습니다. 몇 가지 제품에 대해 계산대에서 기다리는 것을 원하지 않기 때문입니다. 이러한 복잡성을 추가하기 위해 MRL은 600 개가 넘는 슈퍼마켓에 걸쳐 많은 SKU를 보유하고있어 6,000 개 이상의 상점 -SKU 조합으로 이어집니다.
2019 년 말까지 MRL은 기존 통계 방법을 사용하여 각 매장 -SKU 조합에 대한 예측 모델을 생성하여 정확도가 40 %까지 낮아졌습니다. 예측은 여러 개별 모델을 통해 유지되므로 계산 및 운영 비용이 많이 듭니다.
2020 년 초, MRL과 Ganit은 과일 및 채소 (F & V)라고하는 신선한 카테고리를 예측하는 정확도를 더욱 높이고 수축을 줄이기 위해 협력하기 시작했습니다.Ganit은 MRL에게 문제를 두 부분으로 나누라고 조언했습니다.
- 각 상점 -SKU 조합에 대한 수요 예측
- 주문 수량 계산 (들여 쓰기)
다음 섹션에서 각 항목에 대해 자세히 설명하겠습니다.
이 섹션에서는 각 상점 -SKU 조합에 대한 수요 예측 단계에 대해 설명합니다.
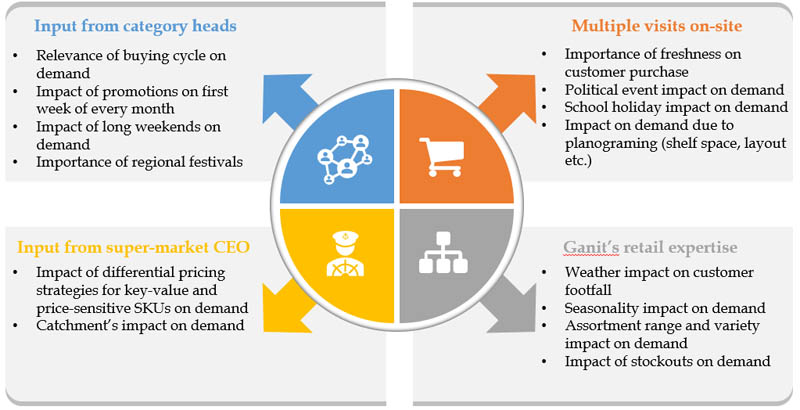
Ganit의 팀은 먼저 매장 내에서 수요를 유도 한 요인을 이해함으로써 여정을 시작했습니다. 여기에는 여러 현장 매장 방문, 카테고리 관리자와의 토론, 슈퍼마켓 CEO와의 케이던스 회의와 계절성, 재고 부족, 사회 경제적, 거시 경제적 요인과 같은 여러 다른 측면에 대한 Ganit의 자체 예측 전문 지식이 포함되었습니다.
매장 방문 후 다양한 요인에 대한 약 80 개의 가설이 식음료 수요에 미치는 영향을 연구하기 위해 공식화되었습니다. 팀은 상관 관계, 이변 량 및 일 변량 분석, 통계적 유의성 테스트 (학생 t- 검정, Z 테스트)와 같은 기술을 사용하여 포괄적 인 가설 테스트를 수행하여 수요와 축제 날짜, 날씨, 프로모션 등과 같은 관련 요소 간의 관계를 설정했습니다.
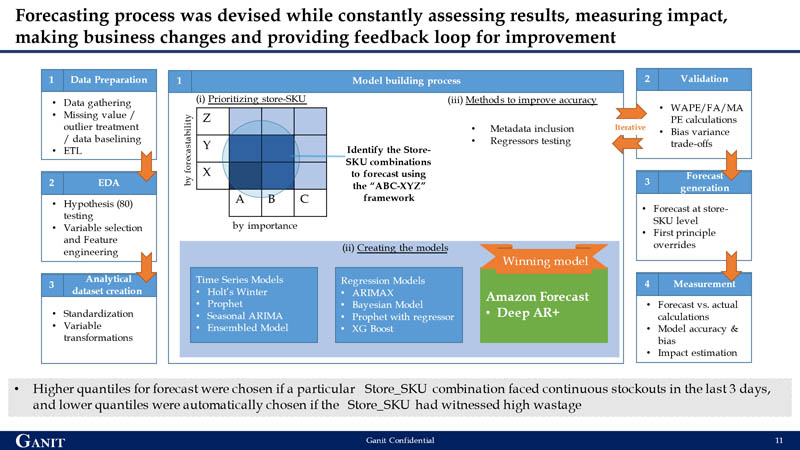
팀은 매일 매장 -SKU 조합을 정확하게 예측할 수있는 세분화된 모델 개발을 강조했습니다. 매출 기여도와 예측 용이성의 조합은 ABC-XYZ 프레임 워크로 구축되었으며, ABC는 매출 기여도를 나타내고 (A는 가장 높음) XYZ는 예측 용이성을 나타냅니다 (Z는 가장 낮음). 모델 구축의 경우 첫 번째 초점은 매출 기여도가 높고 예측하기 가장 어려운 상점 -SKU 조합이었습니다. 이는 예측 정확도 향상이 비즈니스에 최대의 영향을 미치도록하기위한 것입니다.
MRL의 거래 데이터는 휴대폰 번호, 청구서 번호, 품목 코드, 상점 코드, 날짜, 청구 수량, 실현 가치 및 할인 가치와 같은 필드를 사용하여 기존의 POS 데이터처럼 구성되었습니다. 팀은 모델 구축을 위해 지난 2 년 동안의 일일 트랜잭션 데이터를 사용했습니다. 과거 데이터를 분석하면 두 가지 문제를 식별하는 데 도움이되었습니다.
- 수많은 결 측값의 존재
- 어떤 날에는 청구서 수준에서 판매량이 매우 높거나 낮았으며 데이터에 특이 치가 있음을 나타냅니다.
누락 된 값에 대한 심층 분석을 통해 매장에 재고가 없거나 (계절에 공급되지 않음), 계획된 휴일 또는 외부 제약 (예 : 지역 또는 전국 폐쇄 또는 건설 작업)으로 인해 폐쇄되는 매장과 같은 이유를 식별했습니다. 누락 된 값은 0으로 대체되고 적절한 회귀 변수 또는 플래그가 모델에 추가되어 모델이 이러한 미래 이벤트에 대해이를 학습 할 수 있습니다.
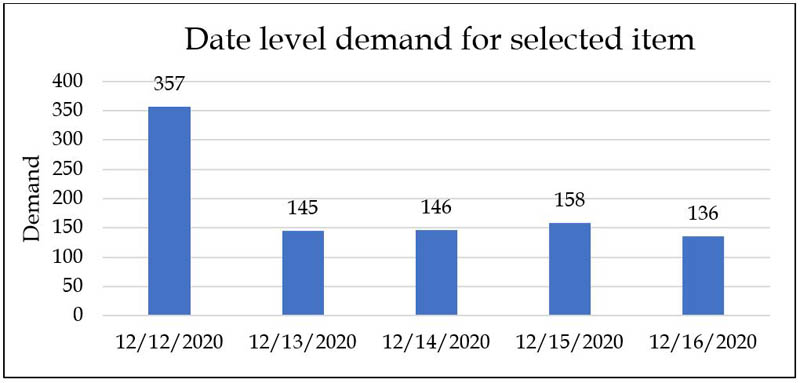
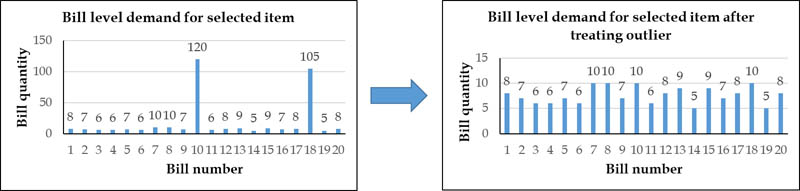
팀은 가장 세분화 된 청구서 수준에서 이상 값을 처리하여 청산, 대량 구매 (B2B) 및 나쁜 품질과 같은 요소를 고려했습니다. 예를 들어, 청구서 수준 처리에는 다음 그래프와 같이 일 수준에서 각 상점 -SKU 조합에 대한 KPI를 관찰하는 것이 포함될 수 있습니다.
그런 다음 비정상적으로 많은 수량이 이상 값으로 판매 된 날짜에 플래그를 지정하고 식별 된 이상 값을 더 자세히 살펴볼 수 있습니다. 추가 분석에 따르면 이러한 이상 치는 사전 계획된 기관 구매입니다.그런 다음 이러한 청구서 수준 이상 치는 해당 날짜의 최대 판매 수량으로 제한됩니다. 다음 그래프는 청구서 수준의 수요 차이를 보여줍니다.
팀은 Forecast를 선택하기 전에 시계열 모델, 회귀 기반 모델 및 딥 러닝 모델과 같은 여러 예측 기술을 테스트했습니다. 예측을 선택하는 주된 이유는 XY 버킷의 예측 정확도를 Z 버킷과 비교할 때 성능 차이 였기 때문에 예측하기 가장 어려웠습니다. 대부분의 기존 기술이 XY 버킷에서 더 높은 정확도를 제공했지만 Forecast의 ML 알고리즘 만이 다른 모델에 비해 10 %의 증가 정확도를 제공했습니다. 이는 주로 다른 SKU (XY) 패턴을 학습하고 이러한 학습을 Z 버킷의 변동성이 높은 항목에 적용하는 Forecast의 기능 때문이었습니다. AutoML을 통해 Forecast DeepAR + 알고리즘이 승자이며 예측 모델로 선택되었습니다.
팀은 Deep AR +를 우승 알고리즘으로 식별 한 후 정확도를 더욱 향상시키기 위해 추가 기능을 사용하여 여러 실험을 실행했습니다. 그들은 순수한 목표 시계열 데이터 (이상 값 처리 포함 및 제외), 축제 또는 상점 폐쇄와 같은 회귀 자, 상점 항목 메타 데이터 (상점 항목 계층 구조)와 같은 다양한 조합을 사용하여 더 작은 샘플 세트에서 여러 반복을 수행하여 최적의 조합을 이해했습니다. 예측 정확도 향상. 이상치 처리 대상 시계열과 상점 항목 메타 데이터 및 회귀 변수의 조합이 가장 높은 정확도를 반환했습니다. 이는 최종 예측을 얻기 위해 원래 6,230 개의 상점 -SKU 조합 세트로 축소되었습니다.
팀이 예측 모델을 개발 한 후 즉시 다음 단계는이를 사용하여 구매 및 주문할 인벤토리의 양을 결정하는 것이 었습니다. 주문 생성은 예측 된 수요, 현재 보유 재고 및 기타 관련 매장 내 요인의 영향을받습니다.다음 공식은 주문 구성을 설계하기위한 기초로 사용되었습니다.
연구팀은 자동주문 시스템의 최소주문량, 서비스단위계수, 최소마감재고, 최소디스플레이재고(플랜그램 기준), 충진율 조정 등 다른 들여쓰기 조정 파라미터도 고려, 기계와 인간의 지능 격차를 해소했습니다.
예측 미달 시나리오와 예측 초과 시나리오의 균형 조정
재고 부족 및 판매 손실 비용으로 축소의 출력 비용을 최적화하기 위해 팀은 Forecast의 분위수 기능을 사용하여 모델에서 예측 응답을 이동했습니다.모델 설계에서 p40, p50 및 p60 분위수에서 세 가지 예측이 생성되었으며 p50은 기본 분위수입니다. 분위수 선택은 최근 과거 매장의 재고 부족 및 낭비를 기반으로 프로그래밍되었습니다. 예를 들어 특정 상점 -SKU 조합이 지난 3 일 동안 지속적인 재고 부족에 직면 한 경우 더 높은 분위수가 자동으로 선택되고 상점 -SKU가 높은 낭비를 목격 한 경우 더 낮은 분위수가 자동으로 선택되었습니다. 증가 및 감소 퀀텀의 퀀텀은 매장 내 재고 부족 또는 축소 정도를 기반으로합니다.
Oracle ERP를 통한 자동화 된 주문 배치
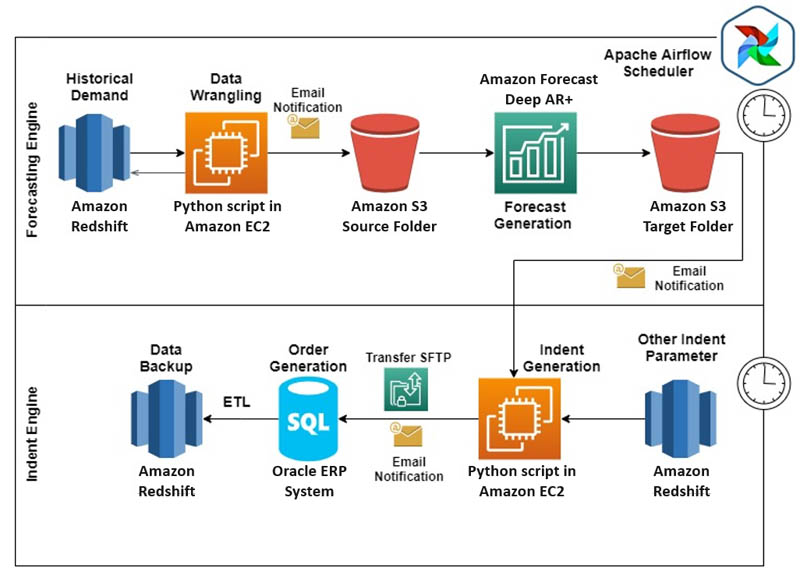
MRL은 Forecast 및 Indent Ordering 시스템을 MRL이 주문 배치에 사용하는 Oracle의 ERP 시스템과 통합하여 프로덕션에 배포했습니다. 다음 다이어그램은 최종 아키텍처를 보여줍니다.
주문 시스템을 프로덕션에 배포하기 위해 모든 MRL 데이터가 AWS로 마이그레이션되었습니다. 팀은 라이브 테이블을 Amazon Redshift (비즈니스 인텔리전스 작업을위한 데이터웨어 하우스) 로 이동하기 위해 ETL 작업을 설정 했기 때문에 Amazon Redshift는 향후 모든 데이터 처리를위한 단일 입력 소스가되었습니다.전체 데이터 아키텍처는 두 부분으로 나뉩니다.
- 예측 엔진 :
- Amazon Redshift에있는 과거 수요 데이터 (1 일 수요 지연) 사용
- 마지막 청구 시간, 가격 및 축제와 같은 다른 회귀 변수 입력은 Amazon Redshift에서 유지되었습니다.
- 아마존 엘라스틱 컴퓨 트 클라우드 (아마존 EC2) 인스턴스는 논쟁 거래, 회귀 및 기타 메타 데이터에 대한 사용자 정의 파이썬 스크립트와 설정
- 데이터 랭 글링 후 데이터는 Amazon Simple Storage Service (Amazon S3) 버킷으로 이동하여 예측을 생성합니다 (모든 상점 -SKU 조합에 대한 T + 2 예측).
- 최종 예측 출력은 S3 버킷의 별도 폴더에 저장되었습니다.
- 주문 (들여 쓰기) 엔진 :
- 예측을 주문으로 변환하는 데 필요한 모든 데이터 (예 : 보유 재고, 저장 수량, 입고 주문의 최근 2 일, 서비스 단위 계수, 플래 노 그램 기반 최소 개장 및 마감 재고)는 Amazon Redshift에 저장 및 유지되었습니다.
- 주문 수량은 EC2 인스턴스에서 실행되는 Python 스크립트를 통해 계산되었습니다.
- 그런 다음 주문을 Oracle의 ERP 시스템으로 이동하여 공급 업체에 주문했습니다.
전체 주문 시스템은 여러 핵심 세그먼트로 분리되었습니다. 팀은 각 프로세스에 대해 Apache Airflow의 스케줄러 이메일 알림을 설정하여 각 이해 관계자가 성공적으로 완료 또는 실패하면 즉시 조치를 취할 수 있도록 알립니다. ERP 시스템을 통해 접수 된 주문은 다음 날 주문을 계산하기 위해 Amazon Redshift 테이블로 이동되었습니다. AWS와 ERP 시스템 간의 통합 용이성 덕분에 사람의 개입없이 완전한 엔드 투 엔드 자동 주문 시스템이 탄생했습니다.
ML 기반 접근 방식은 MRL을위한 데이터의 진정한 힘을 열었습니다. Forecast를 통해 우리는 기존에 사용하던 1,000 개가 넘는 기존 모델과 달리 매장 형식별로 두 가지 국가 모델을 만들었습니다.
예측은 시계열에서도 학습합니다. Forecast 내의 ML 알고리즘은 상점 -SKU 조합 간의 교차 학습을 가능하게하여 예측 정확도를 향상시킵니다.
또한 Forecast를 사용하면 장바구니에있는 항목의 혼합을 기반으로 수요 신호를 보내는 고객과 같은 관련 시계열 및 항목 메타 데이터를 추가 할 수 있습니다. 예측은 들어오는 모든 수요 정보를 고려하고 단일 모델에 도달합니다. 변수 추가로 인해 과적 합이 발생하는 기존 모델과 달리 Forecast는 모델을 강화하여 비즈니스 컨텍스트를 기반으로 정확한 예측을 제공합니다. MRL은 유통 기한, 판촉, 가격, 상점 유형, 풍요로운 클러스터, 경쟁 상점 및 상점 처리량과 같은 요소를 기반으로 제품을 분류하는 기능을 얻었습니다. 공급망 운영을 개선하기 위해 Amazon Forecast를 사용해 보는 것이 좋습니다. 여기에서 Amazon Forecast에 대해 자세히 알아볼 수 있습니다 . Ganit 및 솔루션에 대해 자세히 알아 보려면 info@ganitinc.com으로 문의하십시오. 자세히 알아보십시오.
이 게시물의 내용과 의견은 타사 작성자의 의견이며 AWS는이 게시물의 내용이나 정확성에 대해 책임을지지 않습니다.
저자 정보

Supratim 네르는 는 IS 최고 변혁 책임자 에 더 많은 소매 제한. 그는 벤처 캐피탈 및 사모 펀드 산업에서 일한 경험이 입증 된 경험이 풍부한 전문가입니다. 그는 KPMG의 컨설턴트였으며 AT Kearney 및 India Equity Partners와 같은 조직에서 일했습니다. 그는 하이데라바드에있는 Indian School of Business에서 재무, 일반 MBA를 취득했습니다.
Shivaprasad KT는 는 IS 공동 설립자 겸 CEO 에 Ganit 주식 그는 미국, 호주, 아시아, 인도에서 데이터 과학을 사용하여 외형 및 수익성에 미치는 영향을 제공하는 경험의 17+ 년이있다. 그는 Walmart, Sam ‘s Club, Pfizer, Staples, Coles, Lenovo 및 Citibank와 같은 회사의 CXO에게 조언을했습니다. 그는 뭄바이 SP Jain에서 MBA를, NITK Surathkal에서 공학 학사 학위를 받았습니다.
Gaurav H Kankaria이 는 IS 수석 데이터 과학자 에 Ganit 주식 설계 경험과 소매에 도움이 조직에 솔루션을 구현의 이상 육년을 가지고, CPG, 그리고 BFSI 도메인이 데이터 기반 의사 결정을 내릴 그는. 그는 Vellore에있는 VIT University에서 학사 학위를 받았습니다.