



BLOG

컴퓨터 비전은 저렴한 클라우드 기반 교육 컴퓨팅에 대한 액세스 증가, 성능이 더 뛰어난 알고리즘, 확장 가능한 모델 배포 및 추론을위한 최적화로 인해 인기와 관심을 받고있는 인공 지능 (AI) 분야입니다. 그러나 개별 AI 및 기계 학습 (ML) 도메인의 이러한 발전에도 불구하고 ML 파이프 라인을 일관되고 관찰 가능한 워크 플로로 단순화하여 소규모 비즈니스 단위에서 더 쉽게 액세스 할 수 있도록하는 것은 어려운 목표로 남아 있습니다. 이것은 컴퓨터 비전이 자동화를 통해 생산량을 향상시킬 수있는 강력한 잠재력을 가지고있는 농업 기술 분야에서 특히 그렇습니다. 또한 인간의 농업 기술 근로자가 아닌 AI가 위험한 작업을 수행 할 수있는 건강 및 안전 분야에서도 마찬가지입니다.IntelloLabs , Clarifruit 및 Hectre )와 해충 방제 조치를 가능한 한 일찍 그리고 효율적으로 사전에 목표로 삼는 ( Bayer Crop Science ) 컴퓨터 비전이 강력한 가능성을 보여주는 일부 영역입니다.
설득력이 있지만 머신 비전의 이러한 응용 프로그램은 일반적으로 특정 에지 하드웨어 아키텍처에 대한 기차 컴파일-배포-추론 시퀀스의 복잡성으로 인해 대규모 농업 기업에서만 액세스 할 수 있습니다. 이로 인해 기술과 실무자 사이에 어느 정도 분리가 가능합니다. 그것으로부터 이익을 얻습니다. 대부분의 경우 이러한 단절은 AI / ML의 복잡성이 인식되고 농업, 임업 및 원예와 같은 1 차 부문에서 엔드 투 엔드 애플리케이션을위한 명확한 경로가 부족하기 때문에 발생합니다. 뉴질랜드에서 열린 최근 agtech 프레젠테이션에서, 한 임원은 실험을 위한 제한 요소로서 엔드 투 엔드 AWS 컴퓨터 비전 솔루션의 부족을 강조했는데, 이는 보다 강력한 기술 평가를 위한 조직의 바이-인(buy-in)을 정당화하기 위해 필요할 것입니다.
본 게시글에서는 AWS AI / ML 서비스가 함께 작동하는 방식을 설명하며 레이블이 지정된 이미지를 생성하여, 해당 이미지에 대해 머신 비전 모델을 훈련하고, Amazon Rekognition Custom Labels를 사용하여 사용자 지정 이미지 인식 모델을 배포하는 방법을 구체적으로 보여줍니다 . 이 자습서를 따라 약 1 시간 이내에 사용자 지정 컴퓨터 비전 모델을 시작하고 실행할 수 있어야하며 특정 요구 사항과 관련된 데이터를 기반으로 AI / ML 혁신에 대한 추가 투자에 대해보다 현명한 판단을 내릴 수 있어야합니다.
훈련 이미지 저장
다음 파이프 라인에 표시된대로 사용자 지정 컴퓨터 비전 모델을 생성하는 첫 번째 단계는 모델 학습에 사용하는 레이블이 지정된 이미지를 생성하는 것입니다. 이를 위해 먼저 레이블이 지정되지 않은 교육 이미지를 계정 내의 Amazon Simple Storage Service (Amazon S3) 버킷에로드하고 각 클래스는 버킷 아래의 자체 폴더에 저장합니다. 이 예에서 예측 클래스는 알려진 유형의 이미지가있는 두 가지 유형의 키위 (Golden 및 Monty)입니다. 각 교육 클래스의 이미지를 수집 한 후 Amazon S3 API 또는 AWS Management Console을 통해 Amazon S3 버킷 내의 해당 폴더에 업로드하기 만하면 됩니다.
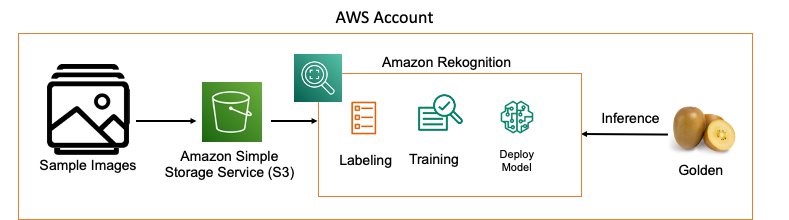
Amazon Rekognition 설정
Amazon Rekognition 사용을 시작하려면 다음 단계를 완료하십시오.
- Amazon Rekognition 콘솔에서 Use Custom Labels를 선택합니다 .
- Get started를 선택 하여 새 프로젝트를 만듭니다.
프로젝트는 모델 및 학습 구성을 저장하는 데 사용됩니다.
- 프로젝트 이름을 입력합니다 (예
Kiwifruit-classifier-project:). - Create을 선택합니다 .
- Datasets 페이지에서 Create new dataset를 선택합니다 .
- 데이터 세트의 이름을 입력합니다 (예 🙂
kiwifruit classifier. - Image location에서 Import images from Amazon S3 bucket을 선택합니다.
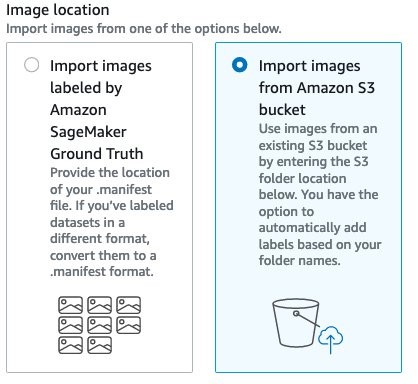
- S3 folder location에서 이미지가 저장되는 위치를 입력합니다.
- Automatic labeling에서 선Automatically attach a label to my images based on the folder they’re stored in을 선택합니다.
즉, 폴더의 레이블이 해당 이미지의 클래스로 각 이미지에 적용됩니다.
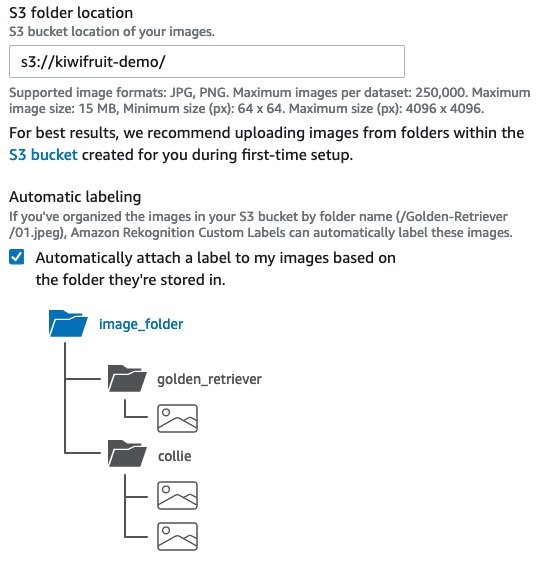
- Policy에서, 아마존 Rekognition 데이터 모델을 양성하는 것을 액세스 할 수 있도록, 아마존 S3 버킷에 제공 JSON을 입력합니다.

- Submit을 선택합니다 .
모델 훈련
이제 해당 이미지가 저장된 폴더 이름을 사용하여 레이블이 지정된 이미지를 성공적으로 생성 했으므로 모델을 훈련 할 수 있습니다.
- 훈련 후 모델이 저장되는 프로젝트를 생성 하려면 Train model을 선택합니다 .
- Choose project에서 당신이 만든 프로젝트의 ARN를 입력합니다.
- Choose a training dataset에서 사용자가 만든 데이터 집합을 선택합니다.
- Create test set에서 Split training dataset를 선택합니다.
이렇게하면 학습 된 모델의 성능을 평가하는 데 사용하기 위해 레이블이 지정된 데이터의 일부가 자동으로 예약됩니다.
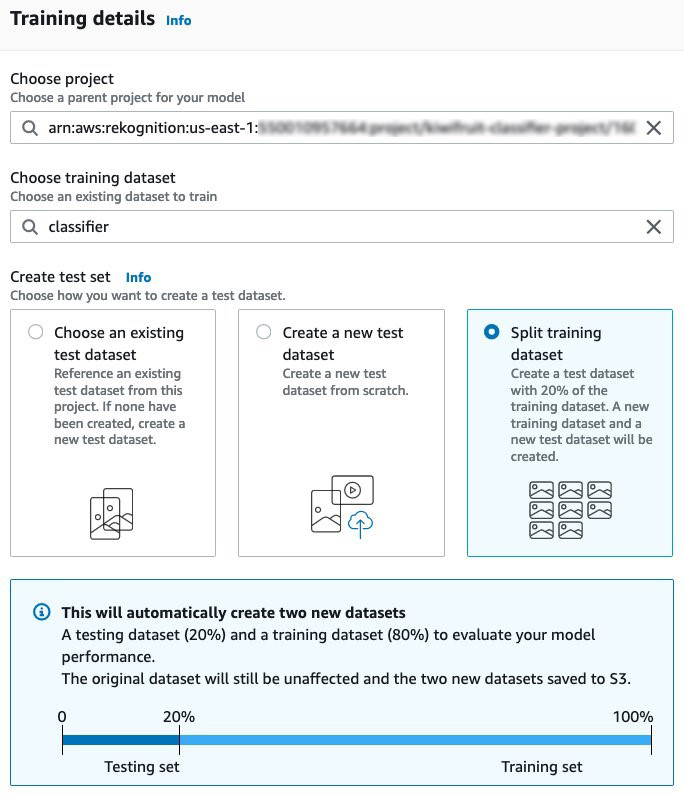
- 훈련 작업을 시작 하려면 Train을 선택하십시오 .
교육에는 시간이 다소 걸릴 수 있으며 (제공 한 레이블이 지정된 이미지 수에 따라) Projects 페이지 에서 진행 상황을 모니터링 할 수 있습니다 .
- 학습이 완료되면 프로젝트에서 모델을 선택하여 각 클래스의 성능을 확인합니다.
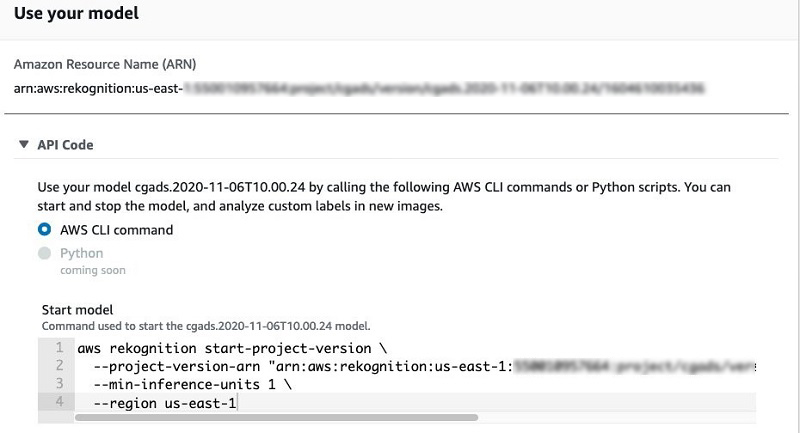
- Use your model에서 API Code를 선택 합니다 .
이를 통해 모델을 시작 및 중지하고 AWS 명령 줄 인터페이스 (AWS CLI)를 사용하여 추론을 수행하는 코드 샘플을 얻을 수 있습니다 .
모델을 시작한 후 추론 엔드 포인트를 배포하는 데 몇 분 정도 걸릴 수 있습니다.
새로 훈련된 모델 사용
이제 만족스러운 훈련 된 모델이 있으므로 추론을 생성하기 위해 제공된 샘플 API 코드를 사용하여 Amazon S3 버킷에서 이미지를 참조하는 것처럼 간단하게 사용할 수 있습니다. 다음 코드는 boto3 라이브러리를 사용하여 이미지를 분석하는 Python 코드의 예입니다.
이미지 추론을 위해 페이로드 의 Name및 Confidence필드에 액세스하려면 JSON 응답을 구문 분석하기 만하면 됩니다.
글을 마치며…
이 게시물에서는 Amazon S3 폴더 레이블 지정 기능과 함께 Amazon Rekognition Custom Labels를 사용하여 이미지 분류 모델을 교육하고, 해당 모델을 배포하고,이를 사용하여 추론을 수행하는 방법을 배웠습니다. 다음 단계는 다중 클래스 분류 자에 대해 유사한 단계를 따르거나 Amazon SageMaker Ground Truth 를 사용 하여 클래스 레이블 외에 경계 상자 주석이있는 데이터를 생성하는 것입니다. 농업에서 컴퓨터 비전을 사용하는 다른 방법에 대한 자세한 정보와 아이디어는 AWS Machine Learning 블로그 및 AWS for Industries : Agriculture Blog를 확인하십시오.
저자 정보
 Steffen Merten 은 뉴질랜드에 기반을 둔 신생 기업의 수석 솔루션 아키텍트입니다. AWS에 입사하기 전에 Steffen은 Palantir에서 내장 분석가로 5 년간 근무한 후 Marsello의 최고 데이터 책임자를 역임했습니다. 또한 그는 중동, 남부 및 중앙 아시아 전역의 미국 국가 안보 산업에서 10 년 이상 생태 및 사회 시스템을 연구하는 복잡한 시스템 분석을 10년 이상 담당했습니다.
Steffen Merten 은 뉴질랜드에 기반을 둔 신생 기업의 수석 솔루션 아키텍트입니다. AWS에 입사하기 전에 Steffen은 Palantir에서 내장 분석가로 5 년간 근무한 후 Marsello의 최고 데이터 책임자를 역임했습니다. 또한 그는 중동, 남부 및 중앙 아시아 전역의 미국 국가 안보 산업에서 10 년 이상 생태 및 사회 시스템을 연구하는 복잡한 시스템 분석을 10년 이상 담당했습니다.
메가존 클라우드 TechBlog는 AWS BLOG 영문 게재 글이나 관련 기사 중에서 한국 사용자들에게 유용한 정보 및 콘텐츠를 우선적으로 번역하여 내부 엔지니어 검수를 받아 정기적으로 게재하고 있습니다. 추가로 번역 및 게재를 희망하는 글에 대해서 관리자에게 메일 또는 SNS 페이지에 댓글을 남겨주시면, 우선적으로 번역해서 전달해드리도록 하겠습니다.